2014-07-30 22:35 Update: I’ve updated the post with the link to netlink RFC. I’ve also replaced references to golang with Go programming language on majority of mentions in the article. I do agree with the people in discussions on the topic of Go/golang, but I’ve adpoted golang in my vocabulary as that’s my standard search term on Google for the information about Go language, hence the abundance of the word golang in the original post.
Long Overdue
When I published the first post on this site some time last year in November about LXC networking I noticed that Docker lacked advanced networking functionality provided in LXC. Docker master extraordinaire Jérôme Petazzoni, who reviewed the post, pointed my attention to pipework. Pipework is a pretty awesome project written entirely in bash which allows you to implement complicated networking setups with Docker.
At the time I was becoming more and more interested in golang, so I thought reimplementing pipework in Go could be a great learning experience. Back then I had only written few small programs in what has become now my most favourite language for one of the companies I worked for and I was looking for a bigger challenge to tackle to improve my skills. Unfortunately a lot of things happened between December last year and now and I only really got back to working “process” properly in mid May. That explains a lack of posts on this site.
Anyways, to cut the long story short, eventually I have decided to NOT reimplement pipework in Go, but rather to create a library which would allow to configure and manage Linux network devices programmatically directly from your Go programs (such as Docker). In this blog post I’ll try to give you an introduction to the project I decided to call tenus which in Latin means something like down to (the problem). You can check the source code of the project on GitHub.
First we need to understand a little bit more about how the management of Linux network devices is implemented in modern Linux tools and then have a look at how the networking is implemented in LXC and Docker.
Netlink
The core of Linux Kernel (just like the core of any other modern Operating System) has a monolithic design for performance reasons as non-essential parts - non-essential for starting and running the kernel - are built as dynamically loadable modules. So the core is monolithic but the kernel itself is modular. Kernel subsystems provide various interfaces to user-space processes/tools to configure and manage them. This reduces the bloat of adding every new feature into the Linux kernel.
Networking implementations in LXC and Docker as well as for example iproute’s make use of the netlink Linux Kernel interface. Before we dive into discussion what tenus can do I’d like give you a tiny introduction to the netlink and hopefully motivate you a little bit to learn more about it as it is one of those fascinating but slightly obscure kernel features!
Netlink is Linux kernel interface which was introduced some time around version 1.3 and then reimplemented around version 2.1. I must admit, I could not find ANY design document or specification when working on this post only the Linux kernel source code and some man pages. But then one of the commenters on Hacker News pointed out the following link which contains full netlink RFC! Wow! I wish I was asking Google the right questions, and paid proper attention to the results! Thanks for pointing this out signa11.
Netlink is a datagram-oriented messaging system that allows passing messages from kernel to user-space and vice-versa. It is implemented on top of the generic BSD sockets so it supports well known calls like socket(), bind(), sendmsg() and recvmsg() as well as common socket polling mechanisms.
Netlink allows 2 types of communication (displayed on the image below):
- unicast - typically used to send commands from user-space tools/processes to kernel-space and receive the result
- multicast - typically the sender is the Kernel and listeners are the user-space programs - this is useful for event-based notifications to multiple processes which might be listening on the netlink socket
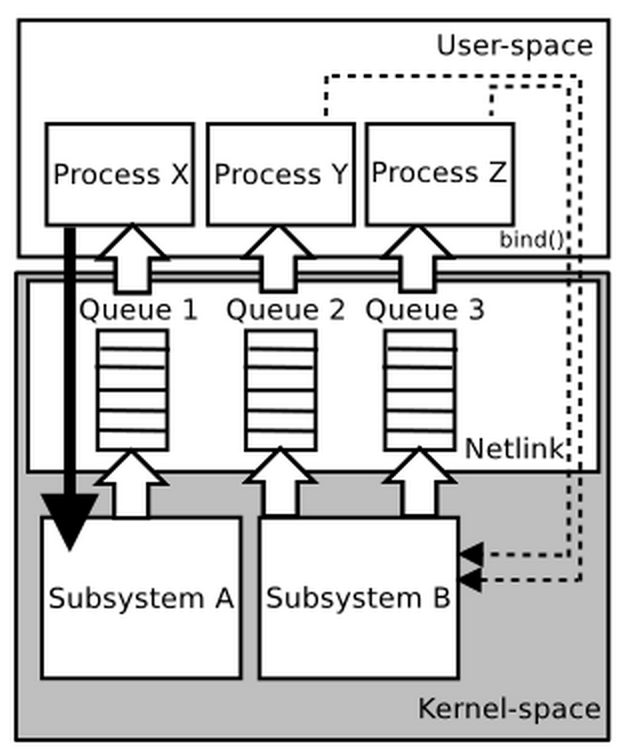
As you can see on the above image, the communication from user-space to kernel-space is synchronous whilst the communication from the kernel to user-space is asynchronous (notice the queues). In other words, when you communicate with Linux Kernel over netlink socket from the user-space, your program will be in a blocking state until you receive the answer back from the Kernel.
We are only going to talk about the unicast communication as that’s the one used in tenus and in the above mentioned containers. In simplified terms it looks like this:
- bind to
netlinksocket - construct a
netlinkmessage - send the
netlinkmessage via socket to the kernel - receive and parse
netlinkresponse from the kernel
Unfortunately netlink does not hide the protocol details to user-space as other protocols do, so you must implement your own netlink message constructs and response parsers yourself.
The main advantages provided by netlink in my opinion are these:
- extensible data format which allows for adding new features without breaking backwards compatibility
- no new kernel syscalls need to be introduced as
netlinkbuilds on BSD sockets - event-based notifications from Kernel to user-space
Currently netlink is mostly used by various networking tools to configure and manage network interfaces, advanced routing, firewalls etc., but there is some use of it in other non-networking kernel subsystems like the ACPI subsystem. Netlink allows up to 32 communication busses in kernel-space. In general each bus is attached to one Kernel subsystem. We are going to focus on its use in Linux network device management bus called rtnetlink.
If you’re interested in netlink programming there is a couple of really good sources (linuxjournal, Neil Horman) which cover the topic pretty well.
LXC, Docker and netlink
Both LXC and Docker containers implement their own netlink libraries to interact with the kernel’s netlink interface. LXC one is written in C (just like the whole LXC project) whilst Docker one is written in Go. Since my primary motivation to create tenus was the curiosity about networking features in Docker and a desire to hack on golang, I’m not going to talk about LXC here. If you are interested in the networking implementation in LXC I’d recommend to look at LXC networking source code on GitHub. The most interesting parts with regards to networking and netlink are on the links below:
I must admit, I hadn’t done any C for a while before I looked at the above source files and I was very surprised how readable the code was. Kudos to Stephane Garber and the whole LXC team for the awesome job on this. Reading LXC source code massively helped me understand better how the networking is implemented in LXC containers and inspired me with regards to how I should approach the implementation of tenus Go package.
Like I said, Docker has its own Go netlink library which it uses to create and configure network devices. The library is implemented as a Go package and is now part of libcontainer. You can have a look at its implementation here. Armed with the knowledge I gained studying netlink I decided to give this a shot and test what it had to offer.
I have created a following Vagrantfile for my tests and started hacking:
$provision = <<SCRIPT
apt-get update -qq && apt-get install -y vim curl python-software-properties golang
add-apt-repository -y "deb https://get.docker.io/ubuntu docker main"
curl -s https://get.docker.io/gpg | sudo apt-key add -
apt-get update -qq; apt-get install -y lxc-docker
cat > /etc/profile.d/envvar.sh <<'EOF'
export GOPATH=/opt/golang
export PATH=$PATH:$GOPATH/bin
EOF
. /etc/profile.d/envvar.sh
SCRIPT
VAGRANTFILE_API_VERSION = "2"
Vagrant.configure(VAGRANTFILE_API_VERSION) do |config|
config.vm.box = "trusty64"
config.vm.hostname = "netlink"
config.vm.provider "virtualbox" do |v|
v.customize ['modifyvm', :id, '--nicpromisc1', 'allow-all']
end
config.vm.provision "shell", inline: $provision
end
I picked Ubuntu Trusty for my tests as it ships with quite a new Linux Kernel. This is important because older kernels ship with slightly buggy netlink interface. As long as you use 3.10+ you should be fine, though:
root@netlink:~# uname -r
3.13.0-24-generic
root@netlink:~#
I quickly put together a simple program which would make use of libcontainer’s netlink package. The program was supposed to create a Linux network bridge called “mybridge”. No more, no less:
package main
import (
"log"
"github.com/docker/libcontainer/netlink"
)
func main() {
if err := netlink.NetworkLinkAdd("mybridge", "bridge"); err != nil {
log.Fatal(err)
}
}
I downloaded the netlink package by running go get and then built and ran the program:
root@netlink:/opt/golang/src/tstnetlink# go get github.com/docker/libcontainer/netlink
root@netlink:/opt/golang/src/tstnetlink# go build mybridge.go
root@netlink:/opt/golang/src/tstnetlink# ./mybridge
2014/07/27 14:59:19 operation not supported
root@netlink:/opt/golang/src/tstnetlink#
Uhh, something’s not right! The network bridge was indeed NOT created as the program failed with error straight after the netlink call. I wondered why, so first thing I did was to check the dmesg as I would expect Kernel to spit out some data into kernel ring buffer:
root@netlink:/opt/golang/src/tstnetlink# dmesg|tail
...
...
[ 2553.121658] netlink: 1 bytes leftover after parsing attributes.
root@netlink:/opt/golang/src/tstnetlink#
I immediately knew that the program was trying to send more data to the kernel than the kernel was expecting. From a very low level point of view when you interact with Kernel’s netlink interface, you essentially send a stream of bytes down the open netlink socket. The stream of bytes comprise a netlink message which contains rtnetlink attributes encoded in the message payload in TLV format. Using the attributes you can tell kernel what you want it to do. So I started looking into the implementation and set out to fix this.

I figured that the problem is most likely related to how rtnetlink attributes are packed into netlink message which is then sent down the netlink socket to th kernel. See, the netlink messages are aligned to 32 bits and contain data that is expressed in host-byte order, so you have to be very careful as you miss one byte or byte-order and you are pretty much screwed. Kernel will “ignore” you in a sense that it will have no clue what you are asking from it!
I pinpointed the problem to be either in func (a *RtAttr) Len() int or func (a *RtAttr) ToWireFormat() methods. After couple of hours reading and re-reading of netlink’s man pages and reading Kernel’s netlink source code (the last time I’ve done this was probably when I was at uni) and various other sources on netlink specification, I thought I had figured it out. I’ve forked the libcontainer repository to verify my assumptions, hacked for a WHILE on it and finally rebuilt the original test program using my libcontainer fork:
package main
import (
"log"
"github.com/milosgajdos/libcontainer-milosgajdos/netlink"
)
func main() {
if err := netlink.NetworkLinkAdd("mybridge", "bridge"); err != nil {
log.Fatal(err)
}
}
Building and running the test program was then pretty much the same routine. Get the forked package, rebuild the program and run it:
root@netlink:/opt/golang/src/tstnetlink# go get github.com/milosgajdos/libcontainer-milosgajdos/netlink
root@netlink:/opt/golang/src/tstnetlink# go build mybridge.go
root@netlink:/opt/golang/src/tstnetlink# ./mybridge
root@netlink:/opt/golang/src/tstnetlink#
Boom! No error! This looks promising! Let’s have a look if the network bridge was actually created:
root@netlink:/opt/golang/src/tstnetlink# ip link list mybridge
88: mybridge: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default
link/ether 8a:7d:1a:c0:93:15 brd ff:ff:ff:ff:ff:ff
root@netlink:/opt/golang/src/tstnetlink#
Wooha! Looks like the fixes I’ve implemented in netlink package worked like charm. I also noticed that Docker hackers must have noticed that the original implementation of func NetworkLinkAdd() didn’t work very well, because they added various network bridge functions to the netlink package which unfortunately have nothing to do with netlink and instead use pure “auld” Linux syscalls.
I’m guessing this is partly because of time constraints to investigate the bugs (this is where we as a community come in!) or it was simply to get network bridging working on older Linux Kernels such as the ones which are shipped with RHEL 6 or CentOS 6 and which come with slightly buggy netlink interface like I mentioned earlier. On these two distros you can’t for example even create a bridge by using well known ip utility by running ip link add name mybridge type bridge. Either way, I believe these bridge related functions should be put somewhere outside of netlink package as they encourage bad practice and simply don’t belong where they are now. But that’s a discussion for maling list and #docker-dev channel, rather than the blog post.
I also noticed that the netlink package was missing the implementation of the advanced networking functionality which is present in LXC and that it also contains few more bugs which had to be fixed before I could start hacking on tenus. I spent couple of nights after work adding these into the package. Once the rtnetlink attributes were correctly packed into the netlink message payload, adding the new functionality was quite easy.
You can have a look at actual implementation in my libcontainer fork. I have of course removed the bridge syscall-based functions from the package because their presence in there was seriously teasing my OCD. Once the core functionality I was after was available in the netlink package I could finally start hacking on my library.
But before we divee into the tenus, let’s quickly have a look at Docker networking. As you probably know by now, when you install Docker on your host and start the docker daemon it creates a network bridge called docker0:
root@netlink:~/# ip link list docker0
5: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff
root@netlink:~/#
When you create a new docker container, docker will create a veth pair and stick one of the interfaces into the container whilst bridging the other interface of the pair against the docker0 bridge. Let’s look at the example. I will create a docker container running /bin/bash:
root@netlink:~# docker run -i -t --rm --name simple ubuntu:14.04 /bin/bash
root@bc08199098f8:/# ip link list
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN mode DEFAULT group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
89: eth0: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 86:21:ab:94:ad:9c brd ff:ff:ff:ff:ff:ff
root@bc08199098f8:/#
Now, when you open another terminal on the host you can verify what I mentioned above:
root@netlink:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
bc08199098f8 ubuntu:14.04 /bin/bash 5 seconds ago Up 5 seconds simple
root@netlink:~#
root@netlink:~# brctl show docker0
bridge name bridge id STP enabled interfaces
docker0 8000.06316b00394b no veth8007
root@netlink:~# ip link list veth8007
90: veth8007: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast master docker0 state UP mode DEFAULT group default qlen 1000
link/ether 06:31:6b:00:39:4b brd ff:ff:ff:ff:ff:ff
root@netlink:~#
There is MUCH more to Docker networking than what I showed here, but all in all it’s a bit of an iptables kung-fu and/or running an extra container (which runs socat inside) on the host or using quite a few different command line options which you need to understand and remember. This is not a criticism! It’s just my personal opinion. Networkin in Docker has gone a long way since December - kudos to the guys at Docker who are working hard on this. I can tell from my own experience it’s not a trivial matter. Either way, I was after something more straightforward, more familiar, something which would offer the simplicity of LXC network configuration, hence I created the tenus.
tenus
I’m not going to talk about the actual package implementation. Go ahead and get shocked by my awful golang code which is available on GitHub. I do admit the code is pretty bad, but it was a great learning experience for me to work on something I was passionate about in my free time. I would welcome any comments and obviously I would love PRs to get the codebase into more sane state than it is now in.
As I mentioned earlier, the package only works with newer Linux Kernels (3.10+) which ship with reasonably new version of netlink interface, so if you are running older Linux kernel this package won’t be of much help to you I’m afraid. Like I said I developed tenus on Ubuntu Trusty Tahr which ships with Kernel 3.13+ and then verified its functionality on Precise Pangolin with upgraded kernel to version 3.10.
Now, let’s do something interesting stuff with the tenus package. I’ve put together a few example programs to help to get you started easily with it. They are located in examples subdirectory of the project. Let’s have a look at one of the examples which creates two MAC VLAN interfaces on the host and sends one of them to a running docker container. First let’s create a simple docker which will run /bin/bash as we did above to show the basic networking. I will name it mcvlandckr :
root@spider:~# docker run -i -t --rm --privileged -h mcvlandckr --name mcvlandckr ubuntu:14.04 /bin/bash
root@mcvlandckr:/# ip link list
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN mode DEFAULT group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
91: eth0: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 92:af:be:4f:2b:3f brd ff:ff:ff:ff:ff:ff
root@mcvlandckr:/#
Nothing extraordinary about the above. As already said, docker creates a veth pair out of which one is sent to the docker container and the other one is bridged against the docker0 network bridge on the host. Now leave the docker running and open a new terminal on the host (the above container is running with -i option i.e. in interactive mode, so it will run in the foreground).
Let’s now build the example program from the source file which is called tenus_macvlanns_linux.go and run it as shown below:
root@netlink:/opt/golang/src/github.com/milosgajdos/tenus/examples# go build tenus_macvlanns_linux.go
root@netlink:/opt/golang/src/github.com/milosgajdos/tenus/examples# ./tenus_macvlanns_linux
root@netlink:/opt/golang/src/github.com/milosgajdos/tenus/examples#
I have also created a gist where you can check out the source code if you prefer that to loading the GitHub page of the project and navigating to examples subdirectory. The program does the following:
- it creates a MAC VLAN interface operating in the bridge mode on the host, names it
macvlanHostIfcand assigns10.0.41.2/16IPv4 address to it - it creates another MAC VLAN interface called
macvlanDckrIfc, again operating in the bridge mode, which is “bridged” to the same host interfaceeth1just likemacvlanHostIfc, sends it to the running docker container called mcvlandckr which we created earlier above and finally assigns10.0.41.3/16IPv4 address to it
The end result of running the example program should be 2 MAC VLAN interfaces - one on the host and another one in the runing docker container “bridged” against the same host interface. Creating MAC VLAN interface on the host and “bridging” it against the same host interface as the docker one was done on purpose so that we can test the connectivity from the host to the container. If you want to know more about how MAC VLAN bridge mode works and why I keep putting doublequotes around the word bridiging in MAC VLAN context, make sure you checkout my previous blog post.
Let’s verify if the program delivers what it promises. First we will check if the macvlanHostIfc interface has been created on the host and if it has a given IP assigned:
root@netlink:/opt/golang/src/github.com/milosgajdos/tenus/examples# ip address list macvlanHostIfc
93: macvlanHostIfc@eth1: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether 46:e4:70:c1:a2:a7 brd ff:ff:ff:ff:ff:ff
inet 10.0.41.2/16 scope global macvlanHostIfc
valid_lft forever preferred_lft forever
inet6 fe80::44e4:70ff:fec1:a2a7/64 scope link
valid_lft forever preferred_lft forever
root@netlink:/opt/golang/src/github.com/milosgajdos/tenus/examples#
Boom! It looks like the host part worked as expected. Now let’s checkout if the other MAC VLAN interface has been created in Docker and if it has the right IP address assigned, too:
root@mcvlandckr:/# ip address list macvlanDckrIfc
94: macvlanDckrIfc@if3: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether 26:57:ce:39:32:8e brd ff:ff:ff:ff:ff:ff
inet 10.0.41.3/16 scope global macvlanDckrIfc
valid_lft forever preferred_lft forever
inet6 fe80::2457:ceff:fe39:328e/64 scope link
valid_lft forever preferred_lft forever
root@mcvlandckr:/#
Awesome! That’s another good sign that all worked as expected. Now, the last check - connectivity. If all went well, we should be able to ping the new IP address allocated to macvlanDckrIfc interface in the running docker. So let’s verify that claim:
root@netlink:/opt/golang/src/github.com/milosgajdos/tenus/examples# ping -c 2 10.0.41.3
PING 10.0.41.3 (10.0.41.3) 56(84) bytes of data.
64 bytes from 10.0.41.3: icmp_seq=1 ttl=64 time=0.038 ms
64 bytes from 10.0.41.3: icmp_seq=2 ttl=64 time=0.044 ms
--- 10.0.41.3 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.038/0.041/0.044/0.003 ms
root@netlink:/opt/golang/src/github.com/milosgajdos/tenus/examples#
Now, if I remove the host’s MAC VLAN interface, I should no longer be able to ping the IP address assigned to the macvlandckr’s MAC VLAN interface:
root@netlink:/opt/golang/src/github.com/milosgajdos/tenus/examples# ip link del macvlanHostIfc
root@netlink:/opt/golang/src/github.com/milosgajdos/tenus/examples# ip l l macvlanHostIfc
Device "macvlanHostIfc" does not exist.
root@netlink:/opt/golang/src/github.com/milosgajdos/tenus/examples# ping -c 2 10.0.41.3
PING 10.0.41.3 (10.0.41.3) 56(84) bytes of data.
--- 10.0.41.3 ping statistics ---
2 packets transmitted, 0 received, 100% packet loss, time 1001ms
root@netlink:/opt/golang/src/github.com/milosgajdos/tenus/examples#
Coo. We can no longer reach the mcvlandckr container from the host via its MAC VLAN interface, so it’s isolated, but it’s also pretty useless because we simply can’t make any use of the newly assigned IP address. So let’s build another docker called mcvlandckr2:
root@netlink:~# docker run -i -t --rm --privileged -h mcvlandckr2 --name mcvlandckr2 ubuntu:14.04 /bin/bash
root@mcvlandckr2:/# ip l l
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN mode DEFAULT group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
9: eth0: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 62:3d:74:f1:94:d9 brd ff:ff:ff:ff:ff:ff
root@mcvlandckr2:/#
It’s pretty identical, but it will do for the prupose of what I want to show you. Now, let’s modify the program which helped us to create MAC VLAN interface for mcvlandckr docker and use tenus to create MAC VLAN interface in the newly created mcvlandckr2 docker container. Here’s the code snippet:
package main
import (
"log"
"net"
"github.com/milosgajdos/tenus"
)
func main() {
macVlanDocker2, err := tenus.NewMacVlanLinkWithOptions("eth1", tenus.MacVlanOptions{Mode: "bridge", MacVlanDev: "macvlanDckr2Ifc"})
if err != nil {
log.Fatal(err)
}
pid, err := tenus.DockerPidByName("mcvlandckr2", "/var/run/docker.sock")
if err != nil {
log.Fatal(err)
}
if err := macVlanDocker2.SetLinkNetNsPid(pid); err != nil {
log.Fatal(err)
}
macVlanDckr2Ip, macVlanDckr2IpNet, err := net.ParseCIDR("10.0.41.4/16")
if err != nil {
log.Fatal(err)
}
if err := macVlanDocker2.SetLinkNetInNs(pid, macVlanDckr2Ip, macVlanDckr2IpNet, nil); err != nil {
log.Fatal(err)
}
}
The source code should look familiar to you if you already checked the gist of the first example. All it does is to create a new MAC VLAN interface inside the new docker and “bridges” it against the SAME host interface as the one created for macvlandckr docker. Now, let’s run it and verify that the interface has indede been created and has the correct IP address assigned as per the above:
root@mcvlandckr2:/# ip address list macvlanDckr2Ifc
13: macvlanDckr2Ifc@if3: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether 1e:7a:5d:53:52:0a brd ff:ff:ff:ff:ff:ff
inet 10.0.41.4/16 scope global macvlanDckr2Ifc
valid_lft forever preferred_lft forever
inet6 fe80::1c7a:5dff:fe53:520a/64 scope link
valid_lft forever preferred_lft forever
root@mcvlandckr2:/#
Awesome! We are almost done here. Now, the interesting part! If all works as expected, both mcvlandckr2 and mcvlandckr dockers should be able to ping each other’s IP assigned to their new network interfaces, whilst still remain to be isolated from the host (remember we have deleted macvlanHostIfc MAC VLAN interface from the host). Now, let’s go ahead and test this.
Connectivity from the host:
root@netlink:/opt/golang/src/github.com/milosgajdos/tenus/examples# ping -c 2 10.0.41.3
PING 10.0.41.3 (10.0.41.3) 56(84) bytes of data.
--- 10.0.41.3 ping statistics ---
2 packets transmitted, 0 received, 100% packet loss, time 1001ms
root@netlink:/opt/golang/src/github.com/milosgajdos/tenus/examples#
root@netlink:/opt/golang/src/github.com/milosgajdos/tenus/examples# ping -c 2 10.0.41.4
PING 10.0.41.4 (10.0.41.4) 56(84) bytes of data.
--- 10.0.41.4 ping statistics ---
2 packets transmitted, 0 received, 100% packet loss, time 1001ms
root@netlink:/opt/golang/src/github.com/milosgajdos/tenus/examples#
Awesome, both dockers remain isolated from the host. Now let’s see if they can reach each other. Let’s try to ping the new IP assigned to mcvlandckr2 from mcvlandckr container:
root@mcvlandckr:/# ping -c 2 10.0.41.4
PING 10.0.41.4 (10.0.41.4) 56(84) bytes of data.
64 bytes from 10.0.41.4: icmp_seq=1 ttl=64 time=0.037 ms
64 bytes from 10.0.41.4: icmp_seq=2 ttl=64 time=0.041 ms
--- 10.0.41.4 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.037/0.039/0.041/0.002 ms
root@mcvlandckr:/#
Boom! Perfect. Now, let’s do the same thing but in the opposite direction i.e. let’s ping the new IP assigned to mcvlandckr from mcvlandckr2:
root@mcvlandckr2:/# ping -c 2 10.0.41.3
PING 10.0.41.3 (10.0.41.3) 56(84) bytes of data.
64 bytes from 10.0.41.3: icmp_seq=1 ttl=64 time=0.036 ms
64 bytes from 10.0.41.3: icmp_seq=2 ttl=64 time=0.057 ms
--- 10.0.41.3 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.036/0.046/0.057/0.012 ms
root@mcvlandckr2:/#
Excellent! We can see based on the above example that tenus can indeed help you to create MAC VLAN interfaces inside your dockers and isolate them from the host or from the other dockers on the host very easily. Let your imagination loose and come up with your scenarios to connect your dockers or simply get inspired by awesome pipework documentation.
If you liked what you saw, feel free to checkout the other examples and the whole project which will show you how to create VLAN interfaces as well an extra VETH pair with one peer inside the docker. I would love if people started hacking on this and improved the codebase massively.
Conclusion
Before I conclude this post, I just want to really stress, that none of what is written in thist post is supposed to criticise the state of networking or any part of the Docker codebase! Although I do admit it might seem like it in some parts. I do appreciate all the hard work which is being done by the tremendous community created around Docker. It also doesn’t mean that the advanced networking as shown here needs to be implemented in the core of Docker. tenus was simply created out of my curiosity and interest in the container networking. I’ll be happy if anyone finds it at least tiny bit useful or even happier if anyone starts hacking on it!
Furthermore, tenus is a generic Linux networking package. It does not necessarily need to be used with Docker. You can use it with LXCs as well or just simply use it to create, configure and manage networking devices programmatically on any Linux host running reasonably new Linux Kernel.
The current state of the package reflects the short time, effort and my rookie knowledge of Go programming language. In other words: I do appreciate it needs quite a lot of work especially around testing and most likely around design, too. Right now the test coverage is not great, but the core functionality should be covered with functional tests. I would massively welcome PRs.
I’m not going to try to get this into the Docker as it looks like the Docker guys have decided to port netlink to C bindings, but I’d love to integrate this into my own Docker fork and test the advanced networking functionality provided by tenus from the core of Docker as oppose to from a separate Go programs. If you are up for this challenge, hit me up! My idea is to come up with new entries in the Dockerfiles which would specify type of networking you want to do with the docker container you are building. But that’s just an idea. Let’s see where we can take this!