Last year I wrote about the superpowers text embeddings can give you and how I tried using them to compare the song lyrics of some music artists. Though the results failed to paint the picture I hoped for – this was due to the methodology, or rather lack thereof – it made me appreciate the importance of simple open source tools (OSS) in the currently booming AI/LLM space.
To get to the point of displaying the embedding projections in the blog post I had to jump through some hoops and combine a lot of different Go modules before I could finally generate the nice interactive plots from the computed data. This wasn’t ideal I knew even back then but I wrote a blog post on a whim trying to quickly prove a silly point to a friend of mine. So at the time, I made do with whatever was necessary.
We need more and better open-source tools to be more effective with this new wave of shiny new tech and I feel like the going is still a bit slow. Other than the usual suspects like ollama and localai that let you run the OSS LLMs locally without much hassle, there is the fantastic llm tool written by Simon Willison whose personal blog is a treasure trove of ideas and in general a tremendous source of empirical LLM knowledge that I often find myself going back to it for references and know-how. Most recently Darren Shepherd introduced the gptscript which lets you “program with natural language”. There are obviously a buttload of more tools I’m not mentioning here, but I feel like most of these tools, as wonderful and useful as they are are made for the nerds like myself, whose primary modus operandi is the command line.
There is absolutely nothing wrong with that – I personally spend a huge majority of my working hours battling various compiler(s) in my terminal, but I feel some tools could use a bit of GUI. This is particularly important if you want to visualise and interact with some data as I did with text embeddings.
When I talk to my friends they immediately point out Jupyter Notebook(JN) and they totally should! There are few tools that have been so instrumental in the data science and machine learning endeavours than JN. Unfortunately, running the JN machinery very often feels like bringing a bulldozer to a knife fight for many tasks. Furthermore, you have to hack together a bunch of Python code with its static typing and pydantic hacks. And don’t get me started on Python tooling – it’s so bad that I think I’d rather chew glass than interact with it [again]. Once you get anything in the Python ecosystem working, do not breathe around it; do not touch its aura and hope things continue to work. But I digress.
Once you get anything in the Python ecosystem working, do not breathe around it, do not touch its aura
Last year, right after I had published the blog post about text embeddings I started hacking on a small side project that would make embeddings explorations easier than the hassle I had to go through. I wanted something you could run locally, ideally in your browser, something that would be self-contained, ideally packaged into a single binary. The tool needed a simple UI and I figured it could be fun to pick up some new React and React Router knowledge along the way, since I had been neglecting mine for far too long.
(Un)Fortunately, I had to abandon the project a few times as I went on rather long holidays, but I never forgot about it. I started hacking on it again a few weeks back on and off in between other things and I think it’s reached a point of utility that it might be worth writing about it. I called it embeviz (an abbreviation of embeddings visualisations) and it’s available on github.
It has two components:
- a backend API written in Go using the GoFiber framework which I had been meaning to take for a spin for a long time!
- a simple web UI written in JS with React and React Router – the (React)JS and CSS are proper ghetto, so ignore that if you will
The UI is embedded into the app, so you have a single binary to interact with; obviously, you must bundle the UI app before you can embed it into the binary. See the README in the repo.
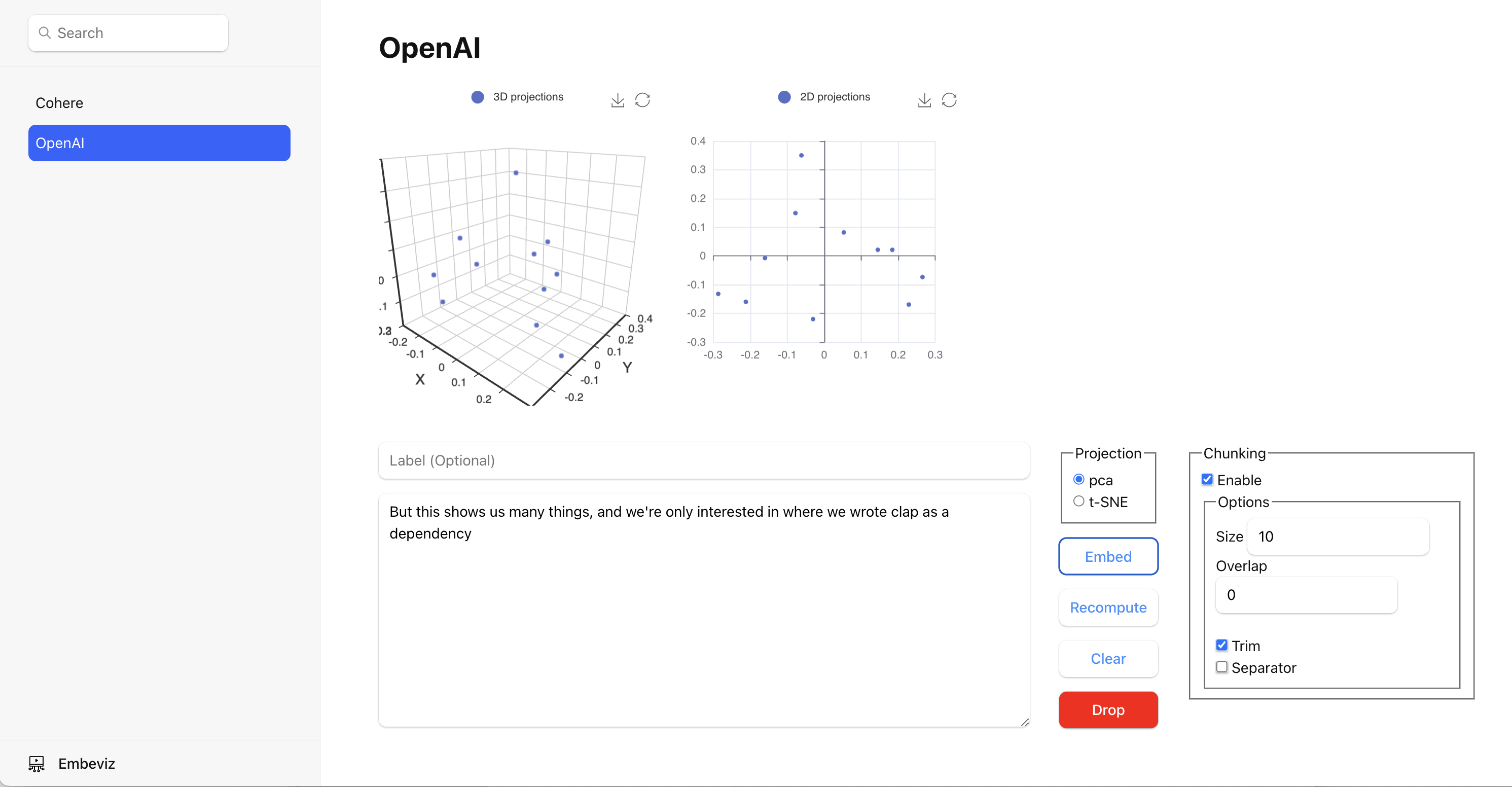
The API is used for communicating with remote LLMs to fetch the embeddings for the text submitted via the web form and to compute their 2D/3D projections. It leverages a Go module I wrote last year which also provides a Go implementation of text splitters – these are basically a plain Go rewrite of the Langchain splitters.
The UI displays the computed projections in simple interactive charts. You can give each text a unique label; by default, a substring of the projected text [chunk] is used for labelling the data in the charts. The tool lets you select a few options for both the projections and chunking. Chunking is by default disabled but if you do enable it we use the Recursive Character Text Splitter for splitting the text in the textarea.
You can see demonstration of some of the features in this Youtube video:
The project also provides a swagger docs for the API, though I wouldn’t recommend interacting with the API directly; there is no websocket/eventing happening between the backend and the UI so smashing a bunch of data in via the API will not automatically update the UI straight away – we must first compute the projections!
By default the app uses a quick-and-ugly-hack in-memory data store, which is literally what I called it: a really really fugly hack, so tread carefully and beware that if you restart the app you’ll lose all the data. Luckily, I hacked on support for a persistent data store, specifically a vector database, since that’s the data we’re processing.
I was considering Postgres and one of its vector database plugins but ended up hacking on qdrant instead as I had been meaning to learn about it for a while but never really found time for it. I figured this was as good of an opportunity to learn about it as ever. They also have a nix package available which made running it locally a breeze.
There is one feature which I particularly liked about qdrant that I’m not sure other vector database providers offer and that is named vectors. What named vectors allow you to do is store multiple vectors per single record. To distinguish the vectors in the record (aka point) you assign them a unique name. You can then fetch them from the collection by that name. This was super handy because it let me store all the vectors related to a single text chunk in a single record (point):
- original text embedding (2k+ dimensions)
- 2D projection (2 dimensions)
- 3D projection (3 dimensions)
With this in place, the tool has become somewhat usable for me personally. As always, if I had to start from scratch I would have done a lot of things differently. Most of the existing code was written in rush last year and when I got back to it a couple of weeks back I couldn’t stop rolling my eyes.
The UI is also very basic, but it does the job. The CSS has always been one of my arch enemies so if you see any “identity theft” (as the frontend engineers refer to the prevalent use of CSS IDs) then call CSS police and tell them to open a PR. The same goes for the Javascript wasteland I’ve laid down in that repo. Sorry, JS friends for I have sinned but I did my best learning React.
Other than fixing the earlier mentioned shortcomings, I’d like to add support for highlighting the text chunks as fed to the
embeddings APIs. I’ve already added a /chunks API endpoint that lets you fetch the indices of the text from the textarea, but I haven’t got
around to adding the JS code which would make the individual chunks color-coded for better understanding of what is being sent to the remote APIs.
That’s it for now, folks, let me know about all the interesting tools you’ve hacked on in the comments. And if you haven’t hacked on any, do it! We’ll all be thankful. Whilst we are arguably going through a bit of an OSS sustainability hangover – I should know I poured a huge amount of my free time and effort last year into releasing OSS registry when really nobody really cares in the grand scheme ot things. I’ve no regrets! Would do it again. And you should too. Hacking on the tools you want to use personally is never a wasted effort! Do it for yourself! I do.