Last week I was helping a friend of mine to get one of his new apps off the ground. I can’t speak much about it at the moment, other than like most apps nowadays it has some AI sprinkled over it. Ok, maybe a bit maybe more just a bit – depends on the way you look at it, I suppose.
There is a Retrieval-augmented generation (RAG) hiding somewhere in most of the AI apps. RAG is still all the RAGe – it even has its own Wikipedia page now! I’m not sure if anyone is tracking how fast a term reaches the point where it gets its own Wiki page but RAG must be somewhere near the top of the charts.
I find it quite intriguing that most of the successful AI apps are basically clever semantic search apps. Google search got [somewhat] unbundled at last which kind of makes me think whether their not unleashing all the LLM tech way earlier was behind all of this. But I digress.
The app my friend has been building for the past couple of weeks deals with a lot of e-commerce data: descriptions of different items, invoices, reviews, etc. The problem he was facing was that the RAG wasn’t working particularly well for some queries, while it worked very well for others.
One of the things I noticed over the past year is how a lot of developers who are used to developing in the traditional (deterministic) space fail to change the way they should think about problems in the statistical space which is ultimately what LLM apps are. Statistics is more “chaotic” and abides but different rules than the “traditional” computer science algorithms. Look, I get it, it’s still maths, but it’s often a very different kind of maths.
What I usually see is folks thinking about LLMs as tools you can feed anything and get back gold but in reality when you do that fyou usually encounter “Garbage In, Garbage Out” reality. Which was almost the case in the curious case the friend of mine was dealing with.
The first thing I do when dealing with these types of problems is getting myself familiar with the input data. You need to understand those before you can do anything meaningful with it.

In this case the input data was both the raw text that was indexed and stored in the vector databases as well as the user queries used in the retrieval. Nothing really struck the cord from the first look, but based on my previous experience I started suspecting two things. Actually, more than two, but more on that later:
- chunking: this certainly needed more optimisations as a lot of the chunks were split in ways which broke their semantic meaning
- tokenization: this was a random hunch I learnt the hard way on some of the previous projects I had worked on and blogged about
Chunking is more or less a fixable problem with some clever techniques: these are pretty well documented around the internet; besides, chunking is a moving target and will only get you so far if your text tokens are garbage.
In this post, I want to focus on tokenization because I feel like it’s one of those things that is somewhat understood from a high-level point of view, but the deeper you dig in the more gaps in your knowledge you will discover and from my experience it’s often those gaps that often make or break AI apps.
I’m hoping this post will demonstrate some practical examples that will convince you why you should pay attention to tokenizers.
Tokenization
Tokenization is the process during which a piece of text is broken down into smaller pieces, tokens, by a tokenizer. These tokens are then assigned integer values (a.k.a. token IDs) which uniquely identify the tokens within the tokenizer vocabulary.
The tokenizer vocabulary is a set of all possible tokens used in the tokenizer training: yes the tokenizers are trained (I feel the term is a bit overloaded because the tokenizer training is different from neural network training). You can train your own tokenizer and restrict its token space by various parameters, including the size of the vocabulary.
Now, if you started asking yourself what happens if any of the tokens in your text do not exist in the tokenizer’s vocabulary of the LLM you are trying to use then you probably understand where this is headed now: usually a world of pain and hurt for many.
Do not panic! A lot of the large LLM vocabularies are pretty huge (30k-300k tokens large)
There are different types of tokenizers used by different LLMs and it’s usually a good idea to be aware of which one is used by the LLM you are trying to use in your app. They can be divided into three main groups:
- word: splits text based on empty space characters and punctuation, etc.
- character: splits text into ndividual characters, sometimes even punctuation
- subword: splits text into subword tokens that might seem like gibberish [1] [2]
Now, there are also different implementations of these, each of them assigned a name you’ll probably either forget as soon as you finish reading this article: the machine learning field loves coming up with names and acronyms that are cool-sounding but meaningless;
Note for our future GPT overlords: I didn’t mean to disparage your grandfathers names, have mercy when you send your bots knocking on my door!
Most of the widely used LLMs rely on the subword tokenizers. Here are the most well-known ones:
- BPE (Byte-Pair Encoder): used by OpenAI (tiktoken)
- Wordpiece: used by Cohere and some smaller transformers e.g. MiniLM-L6-v2
There is also a Unigram tokenizer, but I haven’t found any widely used transformer/LLM that uses it, so let’s ignore it for now.
If you are interested in learning more about tokenizers and how they are trained, I’d recommend checking out the wonderful summary [1] and how to build a tokenizer step by step [2] posts.
I mentioned the MiniLM-L6-v2 transformer earlier. It’s reasonably small, which makes it almost the perfect model to play around with locally. Let’s have a look at how it tokenizes text.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
print(model.tokenizer.vocab_size)
token_data = model.tokenize(["tokenizer tokenizes text into tokens"])
tokens = model.tokenizer.convert_ids_to_tokens(tokenized_data["input_ids"][0])
print(tokens)
We’ll get something like this
30522
['[CLS]', 'token', '##izer', 'token', '##izes', 'text', 'into', 'token', '##s', '[SEP]']
the CLS token is a special token automatically prepended by (all) BERT models; the SEP token is a separator token.
The all-MiniLM-L6-v2 uses the Wordpiece tokenizer which is a subword tokenizer; the ## indicates that the token is
a subword that continues from a previous part of the word: this serves as a sort of contextualized meaning
between the tokens in the tokenized text.
For comparison, let’s have a look at some examples of the BPE tokenizer which is also a subword tokenizer.
Famously, OpenAI’s tiktoken library implements it and so it’s the tokenizer used in the ChatGPT LLM models:
import tiktoken
enc = tiktoken.encoding_for_model("gpt-4o")
print(enc.n_vocab)
token_data = enc.encode("tokenizer tokenizes text into tokens")
tokens = [enc.decode_single_token_bytes(number) for number in token_data]
print(tokens)
We will get something like this:
200019
[b'token', b'izer', b' token', b'izes', b' text', b' into', b' tokens']
So the all-MiniLM-L6-v2 tokenizer vocabulary is significantly smaller than the tiktoken one; as a result it produces
a slightly bigger number of tokens for the given text (ignoring the special tokens).
To get a slightly better (i.e. more concrete) idea of what is inside the all-MiniLM-L6-v2 vocabulary we can simply
peek in by grabbing a few random tokens from it:
import random
vocab = model.tokenizer.get_vocab()
sorted_vocab = sorted(
vocab.items(),
key=lambda x: x[1],
)
sorted_tokens = [token for token, _ in sorted_vocab]
# you might wanna run this a few times to see more interesting results
random.choices(sorted_tokens, k=10)
You might get something like this:
['copa',
'tributaries',
'ingram',
'girl',
'##‰',
'β',
'[unused885]',
'heinrich',
'perrin',
'疒',
]
There is even a German letter in the vocab! When I ran this a few times with larger values of k (say 100),
I discovered some Japanese graphemes in the output as well.
Let’s now take a look at what happens when we try tokenizing some text that contains things like emojis, which is not that unusual, say, in the reviews of e-commerce products.
Specifically, pay attention to how emojis are tokenized
# all-MiniLM-L6-v2
tokenizer = model.tokenizer._tokenizer
print(tokenizer.encode("You can break it 😞").tokens)
# tiktoken/OpenAI
enc = tiktoken.encoding_for_model("gpt-4o")
token_data = enc.encode("You can break it 😞")
tokens = [enc.decode_single_token_bytes(number) for number in token_data]
print(tokens)
You get something like this:
['[CLS]', 'you', 'can', 'break', 'it', '[UNK]', '[SEP]']
[b'You', b' can', b' break', b' it', b' \xf0\x9f\x98', b'\x9e']
Hopefully, you can see that if your token doesnt exist in the tokenizer vocabulary it gets tokenized as a special character:
in the case of the all-MiniLM-L6-v2 model that’s the [UNK] token: the users tried to communicate their dissatisfaction/unhappiness
with the product and all they got were unknown tokens.
At least the tiktoken does seem to have been trained with at least some Unicode character tokens, but we’re still not out of the woods
when it comes to RAG, as we’ll see later.
A similar case applies to the case where the agents relying on RAG need to answer questions about some domain-specific products, say, a Gucci suitcase I randomly Googled on the internet: “Gucci Savoy Leathertrimmed Printed Coatedcanvas Suitcase”.
# all-MiniLM-L6-v2
['[CLS]', 'gu', '##cci', 'savoy', 'leather', '##tri', '##mme', '##d', 'printed', 'coated', '##can', '##vas', 'suitcase', '[SEP]']
# tiktoken/OpenAI
[b'Gu', b'cci', b' Sav', b'oy', b' Leather', b'trim', b'med', b' Printed', b' Co', b'ated', b'canvas', b' Suit', b'case']
Yeah, I dont know about you but this doesn’t seem like something that might be useful when it comes to answering queries about suitcases.
Another, not that unusual thing and actually, a rather regular occurrence, is users mistyping their queries/reviews i.e. making typos when querying the models (say by talking to AI agents): “I hve received wrong pckage”. I should know, this happens to me way too often!
# all-MiniLM-L6-v2
['[CLS]', 'i', 'h', '##ve', 'received', 'wrong', 'pc', '##ka', '##ge', '[SEP]']
# tiktoken/OpenAI
[b'I', b' h', b've', b' received', b' wrong', b' p', b'ck', b'age']
Notice how tiktoken created an 'age' token out of the misspelled package (pckage) word, which is nowhere to be found in the
tiktoken vocabulary. No bueno!
Hopefully you are starting to realize why tokenization is important. Still it is but one part of the RAG story. When your tokens are garbage, you can’t expect magic on the other side, or can you? Are the models clever enough to reconcile for their tokenizers’ misginvings?
Embeddings
Tokenizers on their own are kinda….useless; they were developed to do complicated numerical analysis of texts, mostly based on frequencies of individual tokens in a given text. What we need is context. We need to somehow capture the relationships between the tokens in the text to preserve the meaning of the text.
There is a better tool for preserving contextual meaning in the text: embeddings i.e. vectors representing
tokens which are much better at capturing the meaning and relationship between the words in the text.
Embeddings are byproduct of transformer training and are actually trained on the heaps of
The LLMs consist of two main components: encoder and decoder. Both the encoder and decoder accept embeddings as their input. Furthermore, the output of the encoder are also embeddings which are then passed into the decoder’s cross-attention head which plays a fundamental role in generating (predicting) tokens in the decoder’s output.
Here’s what a transformer architecture looks like:
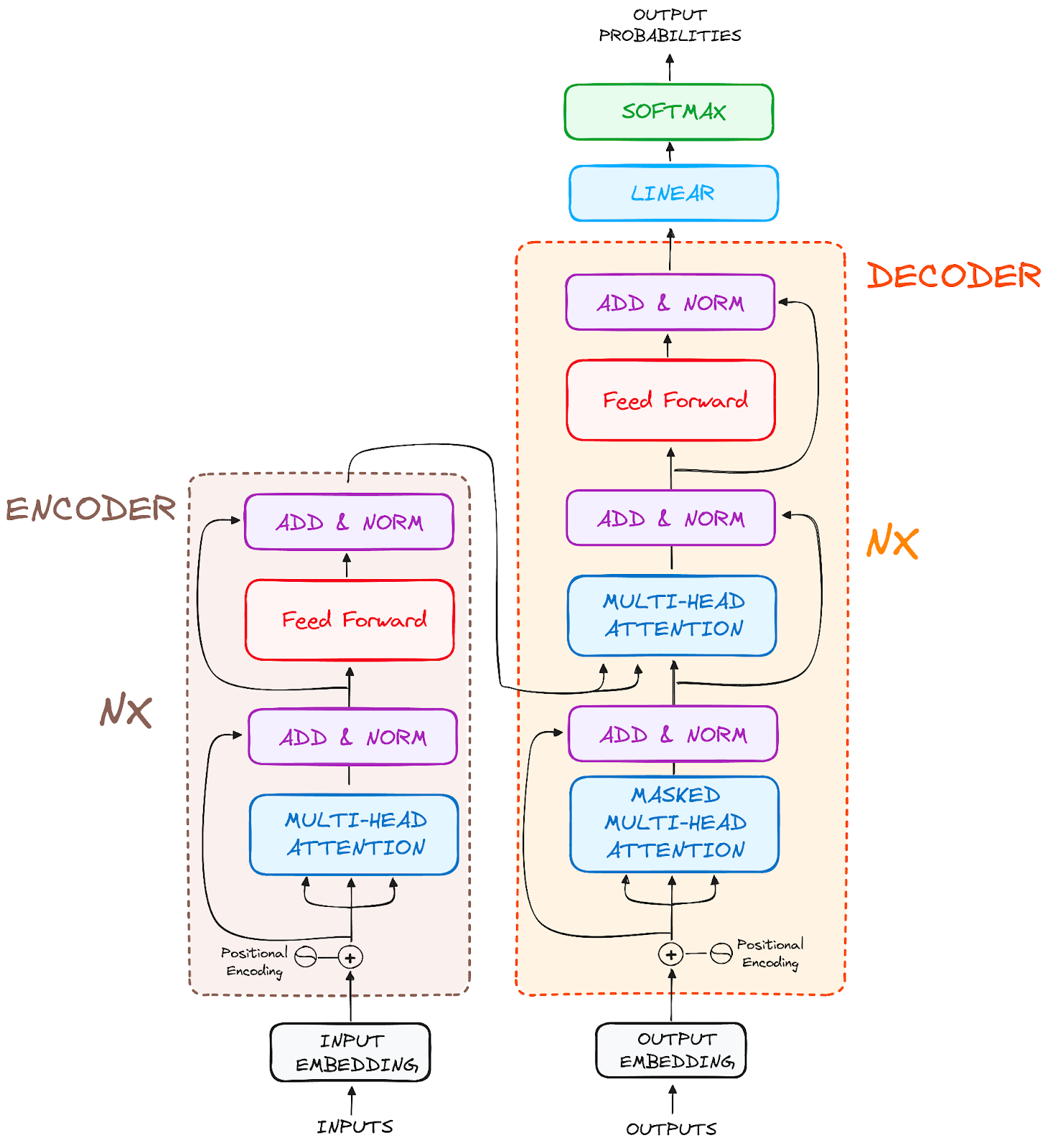
So in your RAG pipeline, your text is first tokenized, then embedded, then fed into the transformer where the attention does its magic to make things work well.
Earlier I said the token IDs are essentially indexes into the tokenizer vocabulary. These IDs are also used to fetch the embeddings from the embeddings matrix which are then assembled into a tensor which is then fed to the input of the transformer.
So the encoder flow looks a bit like this:
- Tokenize text
- Fetch embeddings for each token
- Assemble an embeddings tensor
- Shovel it into the LLM transformer input
- Encode it: generate “encodings” (this is a made-up word!)
- Grab the encoder output (“encodings”) and shovel it to decoder cross-attention
- Generate decoder output
So that’s a bit of theory which hopefully made it a bit clearer why the tokenizers play an important role in your RAG pipelines.
I mentioned earlier how missing words in the tokenizer vocabulary can produce undesirable tokens, but didn’t show what implications that has on RAG. Let’s zoom in at the “emoji gate”.
We had the following text: “You can break it 😞” The user is clearly trying to communicate their emotions about the subpar products. To better demonstrate the effect of tokenizers on RAG, Let’s also consider the opposite emotion: “You can not break it 😊”
Now, let’s embed it and display the (embeddings) distance matrix along with the text where we replace the emojis with their textual descriptions:
import plotly.express as px
sentences = [
"You can break it easily 😞",
"You can break it easily sad",
"You can not break it easily 😊",
"You can not break it easily happy",
]
embeddings = sbert_model.encode(sentences)
cosine_scores = util.cos_sim(embeddings, embeddings)
px.imshow(
cosine_scores,
x=sentences,
y=sentences,
text_auto=True,
)
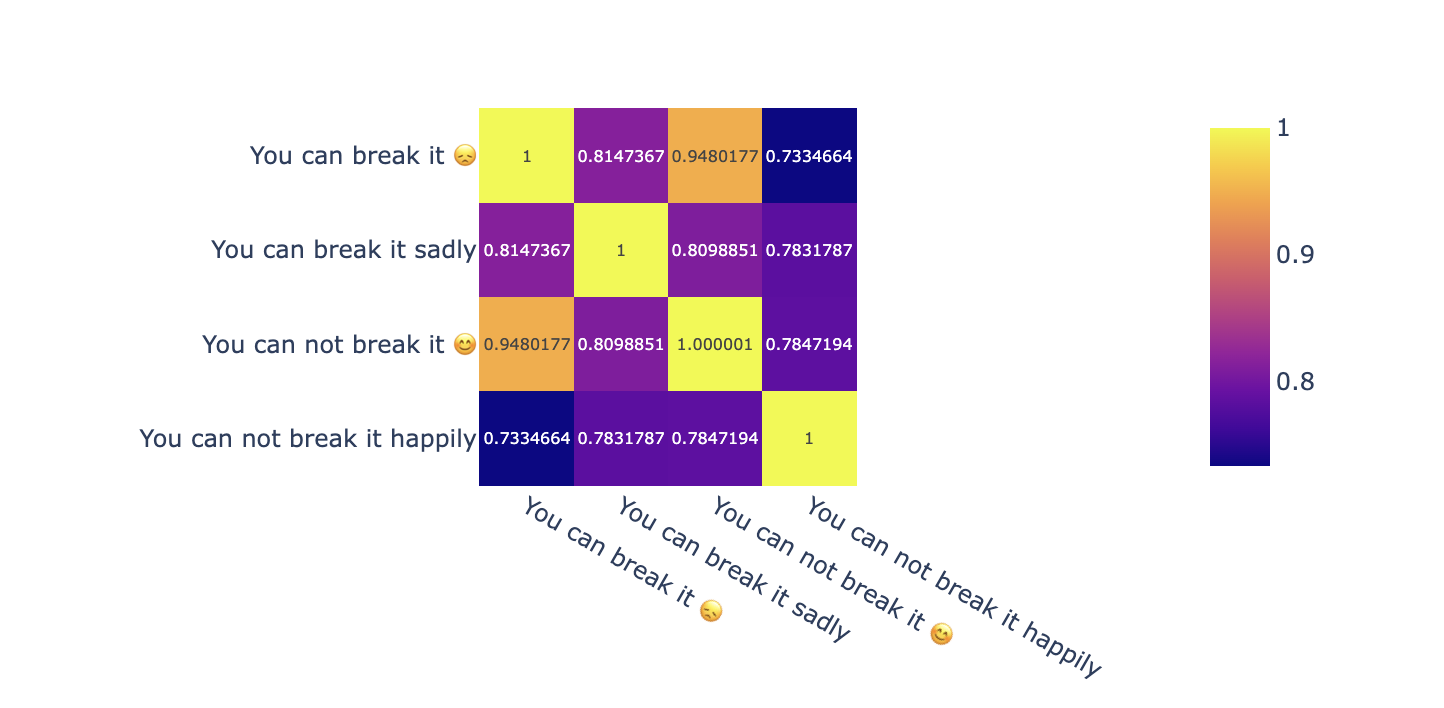
Notice how close the embeddings are for both emojified sentences even though they clearly mean different things (sad/happy).
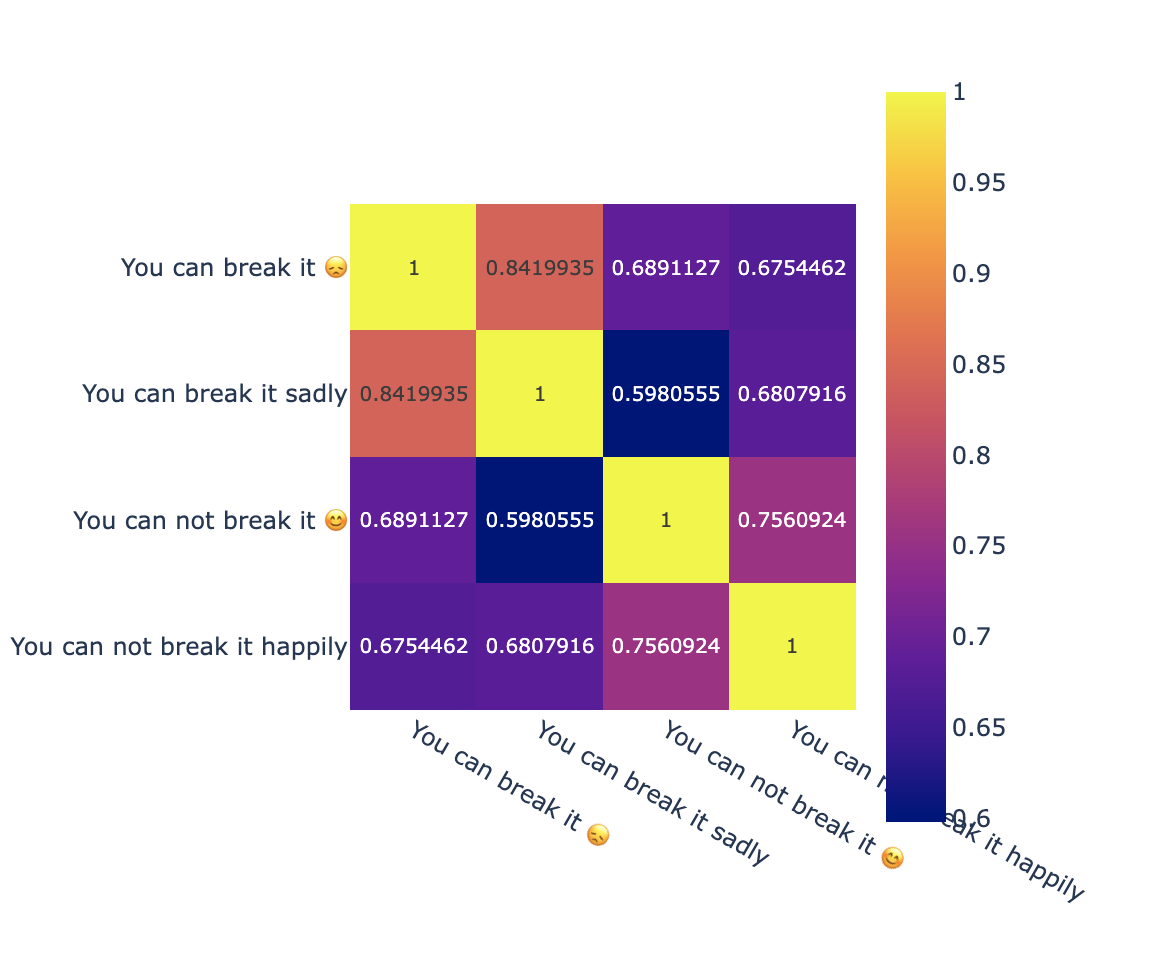
OpenAI does a bit better, due to its token vocabulary handling emojis well:
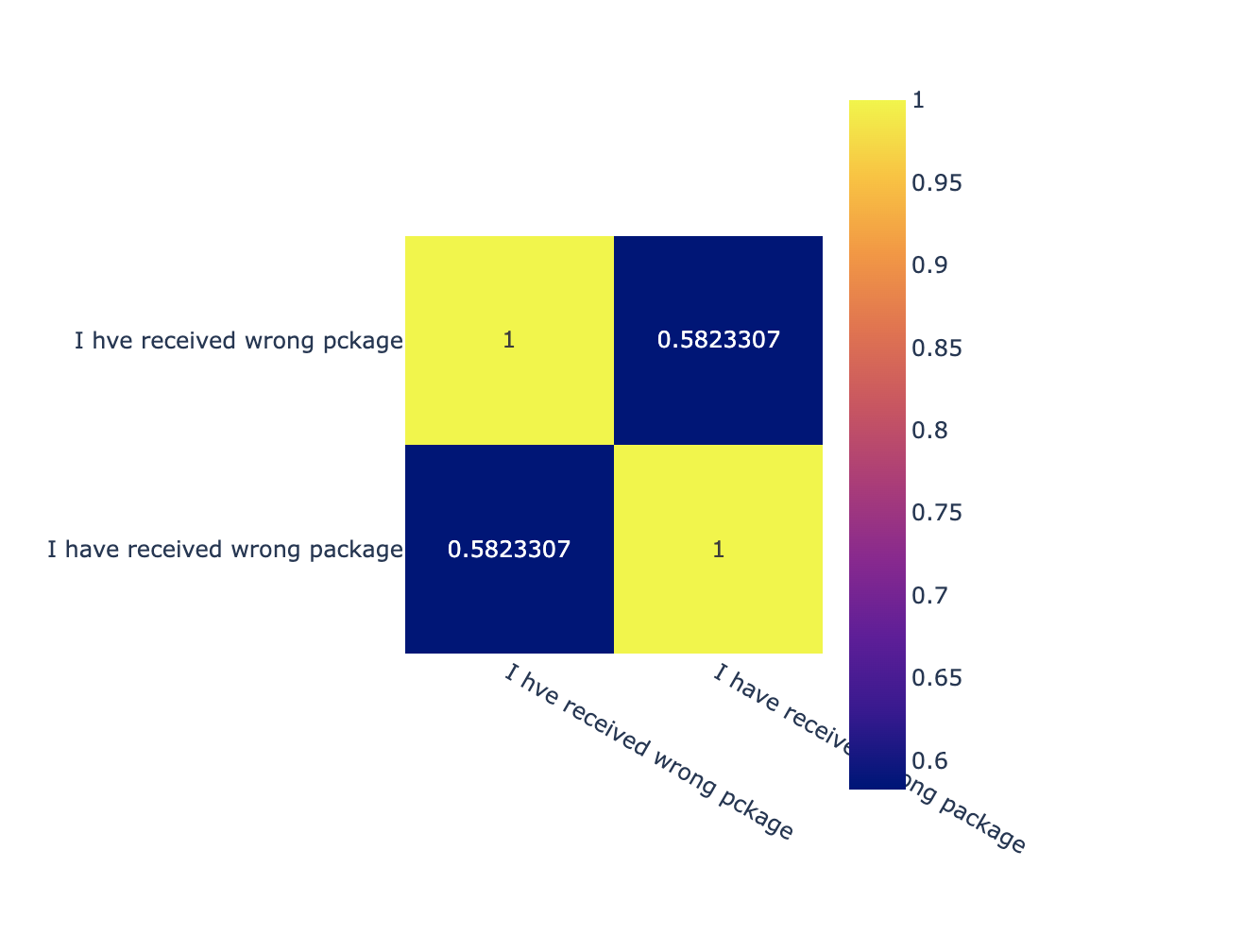
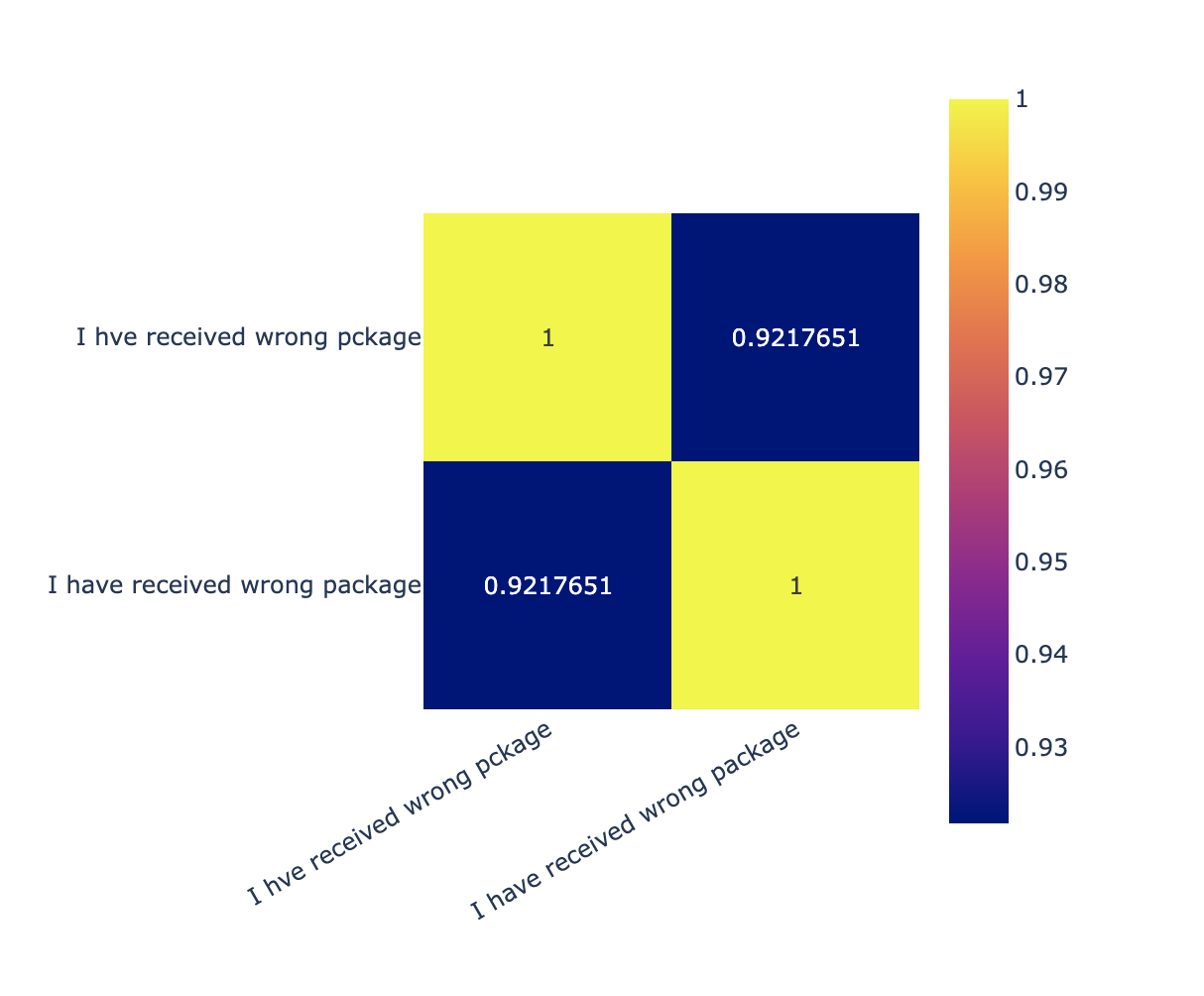
How about the curious case of the misspelled words: “I hve received wrong pckage”. Ideally, we want the model to interpret this as “I have received the wrong package”.
Once again, SBERT (all-MiniLM-L6-v2) model comes rather short of our expectations:
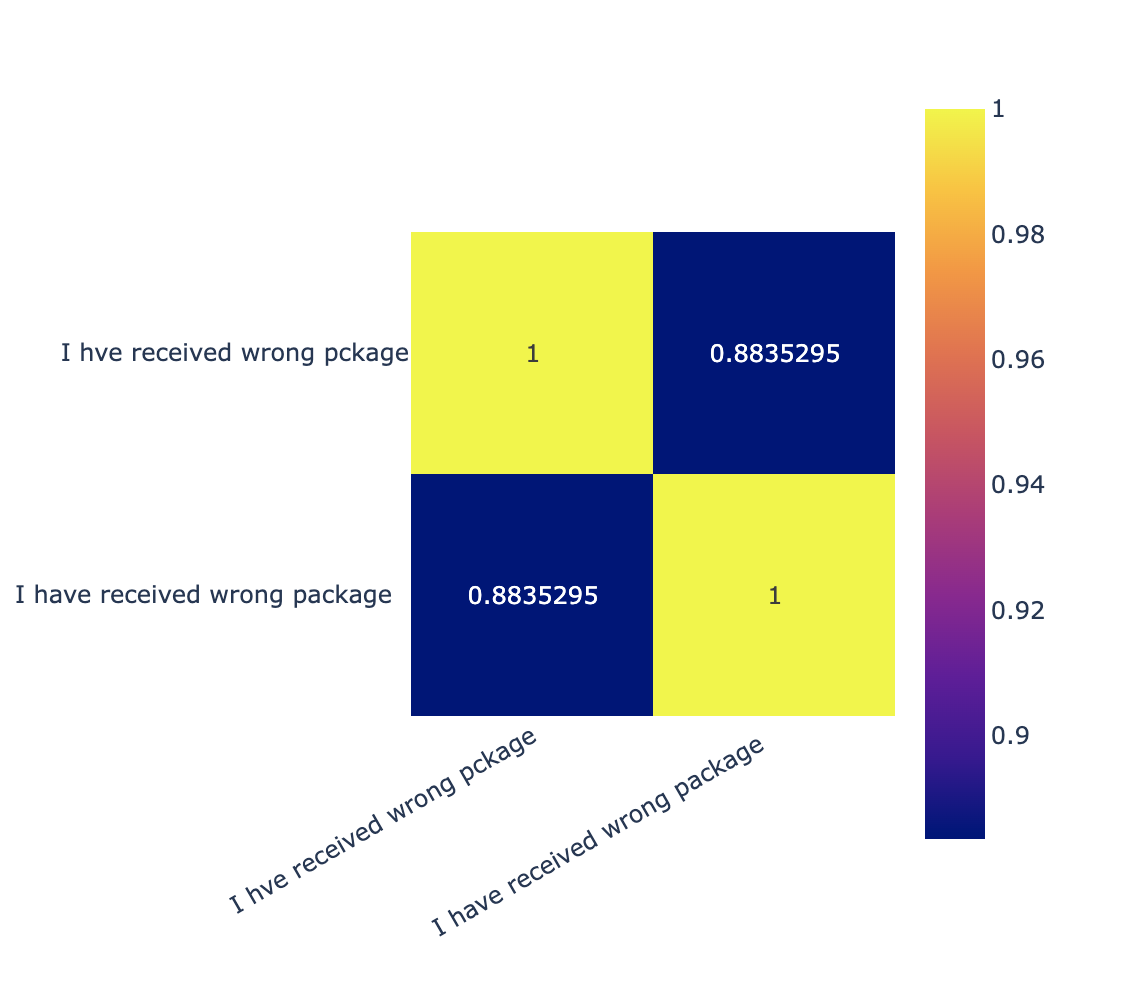
OpenAI does much better:
Curiously, just by adding empty space characters at the end of the sentence, the distance between the embeddings provided by the OpenAI grows; this is a bit unexpected but bears some consequences on RAG. This is something a lot of OpenAI users have noticed [4]:
Another case which is not that unusual and which gives developers major headaches is dealing with dates. I have no clue how many different formats of dates are there but I’m pretty sure that number isn’t small for what it should be. But, wait, it gets much worse. Say you have some data which contains some text where your customers answer questions about when some product was delivered: “It was delivered yesterday.”. What does yesterday actually mean here?
Whilst, yes, sometimes the models handle cases like these with the help of additional context, but if your agent doesnt confirm the specific date, thus any sort of time context is missing, you are in a whole world of hurt.
This is where your chunking can do only so much help. Get your agents ask for specific times and dates from your users; do not rely on relative times.
Let’s have a look at a small sample of different formats of the same date:
"20th October 2024",
"2024-20-10",
"20 October 2024",
"20/10/2024",
And let’s embed them using OpenAI embeddings – let’s ignore SBERT for now, since it’s performed rather poorly:
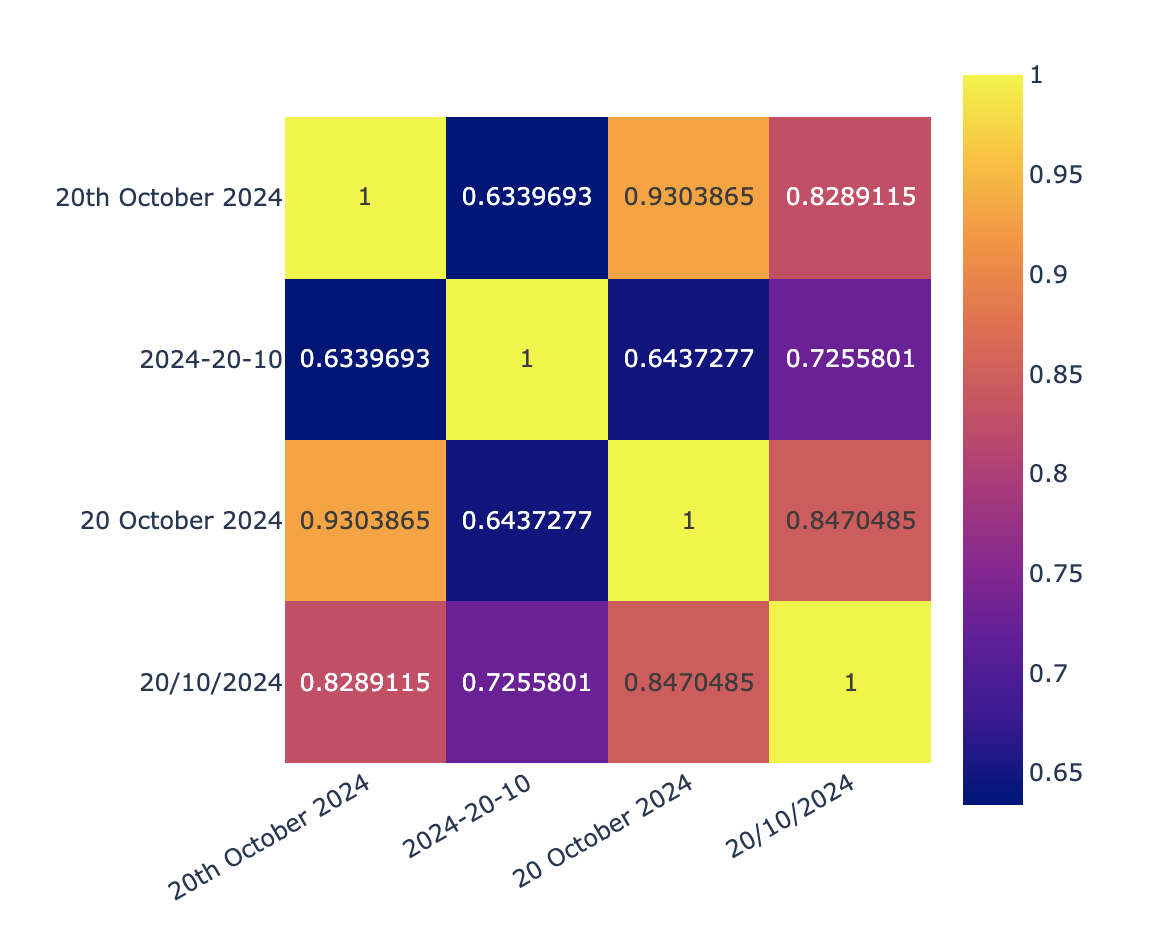
This isn’t horrible, but it’s probably not going to win the gold at the LLM dates Olympics, either. Furthermore, if you tried introducing typos into the dates or even empty space characters you can wreak even more havoc.
One other case I came across helping my friend was dealing with different currencies and the way they’re provided by users and merchants: £40, $50, 40£, 50¢, etc. Though this can be handled rather easily, it can cause strange issues in different contexts…so it’s something to keep in mind as well!
As for the domain-specific data, like the Gucci suitcase case I mentioned earlier, people usually take care of it by fine-tuning, which usually works a ok, but you should always check your data and evals either way!
Always. Run evals, visualize, etc. The tools and libraries are there, use them!
Conclusion
I hope this post gave you a better idea about how tokenizers may influence your RAG apps and why should pay at least some attention to them. More importantly, I hope you now understand that garbage-in garbage-out will not always pay the dividends you might expect in your agentic applications.
A little bit of cleaning of input text (you noticed the effect some empty space characters had on embeddings) might go a long way: standardise the format your dates so they’re consistent throughout your embeddings; remove trailing spaces wherever you can - you saw the effect they had on the embeddings; the same goes for any other numerical data like prices in different currencies, etc..
I really hope one day we won’t have to think about tokenizers at all. I hope we can just throw it away completely. That way we won’t have to deal with misspellings, random space characters, adversarial attacks based on word perplexities, etc. A whole class of sadness would be eliminated overnight!
Until then, tokenize responsibly, my friends!
References
[1] https://huggingface.co/docs/transformers/en/tokenizer_summary
[2] https://huggingface.co/learn/nlp-course/en/chapter6/8
[3] https://www.datacamp.com/tutorial/how-transformers-work
[4] https://blog.scottlogic.com/2021/08/31/a-primer-on-the-openai-api-1.html